芯片耗电"触目惊心"
"LLM大模型单训练集群由2023年的 千卡规模(GPT-3、Llama-2)迅速发展到 万卡规模(Llama-3)甚至 十万卡规模(xAI、GPT-5)"
"单芯片 耗电增长迅速,我们无法在同一州放置超过10万片H100进行GPT-6的训练,否则会导致 电网崩溃"

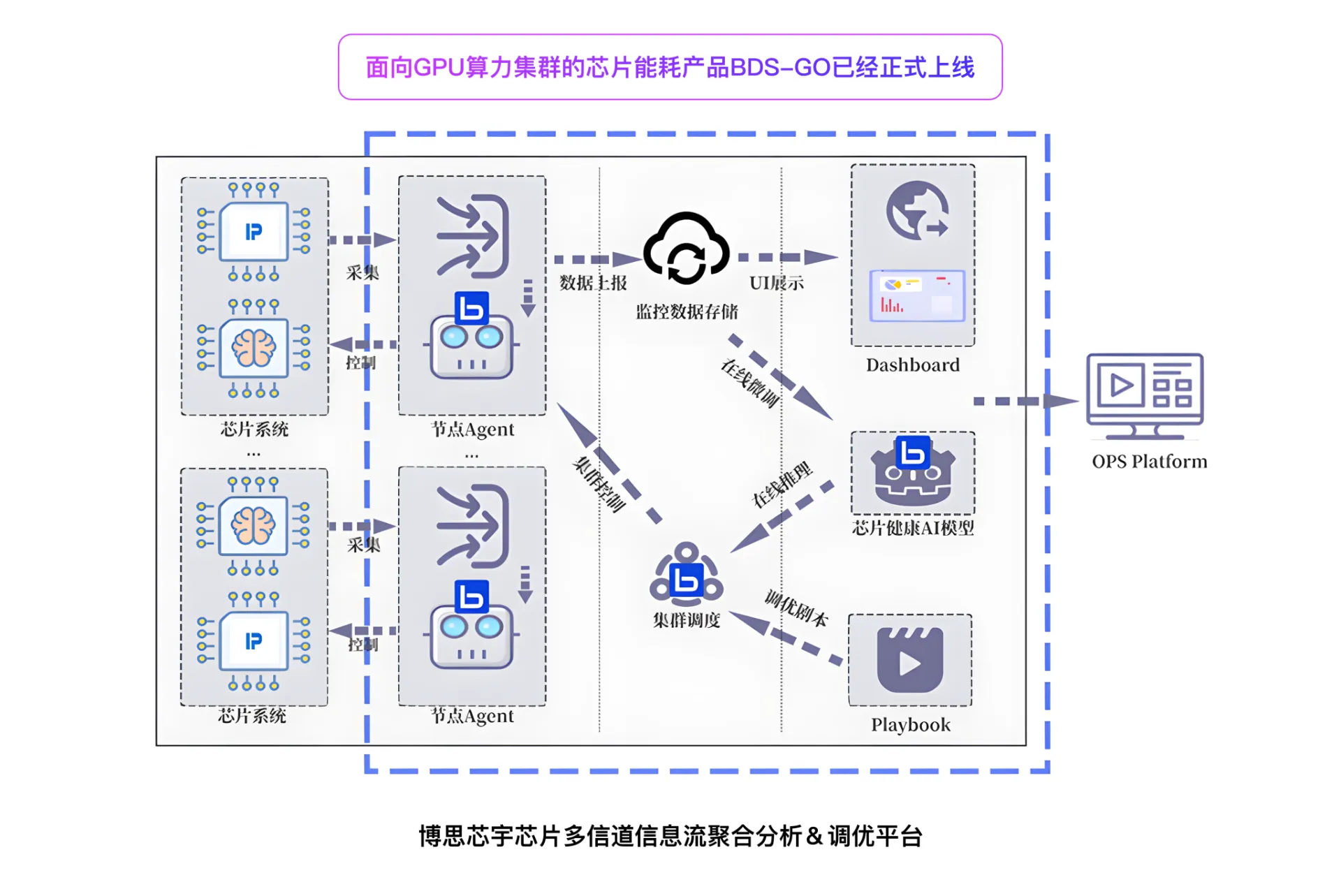
因此我们平台的优势
BDS-GO: 芯片能耗降低
平均每100台8卡Nvidia H100算力服务器
¥100w-¥160w
每年可节约电费
712.5吨
减少碳排放
平均每100台8卡Nvidia H100算力服务器
¥60w-¥110w
每年可节约电费
427.5吨-783.8吨
减少碳排放

18%
基于芯片健康状态分析的常规模式平均

32%+
叠加基于侧信道分析的Boost模式平均


BDS-GO: 核心温度降低
降低GPU核心温度: 减小液冷、空调等设备降温压力,有效 降低 数据中心整体 PUE 有效 延缓芯片老化,保障 芯片服役 末期性能 防止芯片由于温度过高而掉频、掉卡,减轻运维压力